
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 미래는_현재와_과거로
- 문자열
- 세그먼트 트리
- 백트래킹
- 가끔은_말로
- tensorflow
- Overfitting
- 이분 탐색
- DP
- NEXT
- 다익스트라
- 분할 정복
- lazy propagation
- dfs
- 알고리즘
- 플로이드 와샬
- 우선 순위 큐
- pytorch
- 조합론
- 가끔은 말로
- back propagation
- c++
- 2023
- object detection
- 회고록
- 자바스크립트
- dropout
- BFS
- 크루스칼
- 너비 우선 탐색
- Today
- Total
Doby's Lab
Activation이 Non-linearity를 갖는 이유 본문
✅ Intro
지금까지 hidden layer의 구조가 들어간 MLP의 모델을 만들 때, 너무 당연하게 hidden layer에도 Activation을 추가해 주었었습니다. Activation에 대해서는 output layer에 추가하는 것 밖에 배우지 않았는데도 말입니다.
또한, Batch Normalization에서 Activation에서의 Non-linearity 상실이 좋지 않은 문제로 다루는데 왜 그런지도 알고 싶었습니다.
그래서 이번엔 hidden layer에서의 Activation의 역할에 대해 알아보려 합니다.
✅ Non-linear Model
모델은 linear의 관점에서 linear model과 non-linear model로 나뉩니다.
즉, 선형적으로 분류하는가 비선형적으로 분류하는가의 차이입니다.
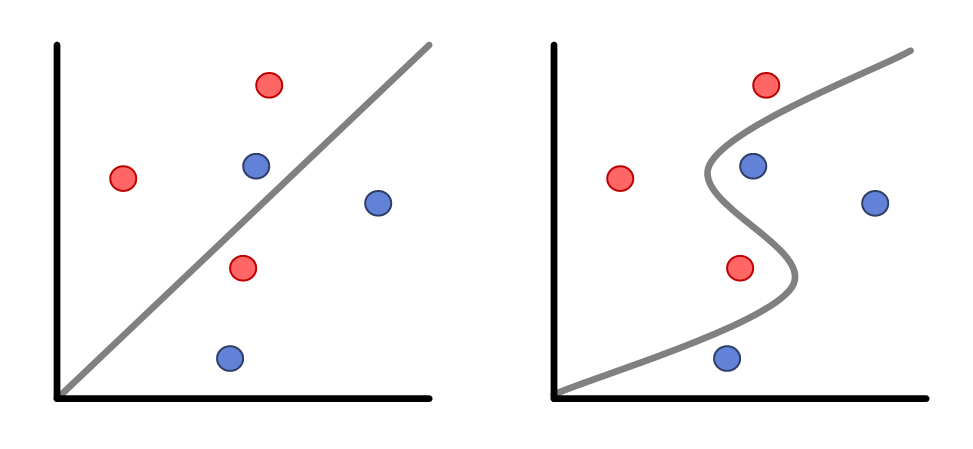
두 분류기의 그림을 가져와봤습니다. 왼쪽은 Linear Model, 오른쪽은 Non-linear Model입니다.
그림으로 보았을 때, Non-linear Model이 더 분류를 잘하는 것을 알 수 있습니다.
Non-linear Model이 분류를 더 잘하는 이유는 선형적인 모델보다 더 복잡성을 가짐으로써 더 분류를 잘할 수 있게 된 것입니다.
모델에서 이러한 복잡성을 갖도록 하는 것이 Activation의 역할이기도 합니다.
Activation을 비선형적 함수로 가짐으로써 모델의 복잡성을 더 늘리게 됩니다.
✅ hidden-layer
은닉층에서 관점에서 보았을 때, Activation을 비선형적 함수로 사용하는 이유에 대해서 알아보겠습니다.
각 층에 대한 출력을 \(h(x) = Wx + b\)라고 가정해 봅시다.
만약에 3번의 층을 지나면 \(h(h(h(x))) = W*W*W*x\)입니다.
\(W^3 = c\)로 정리할 수 있습니다. 이로 인해 \(h(h(h(x))) = cx\)인 그저 상수배가 되는 선형적인 함수가 되는 것입니다.
이렇게 되면 층을 깊게 쌓을 필요가 없어집니다. 왜냐하면 선형적인 함수가 됨으로써 하나의 층을 통과한 것처럼 보이니까요. (물론 층을 깊게 쌓는 것에 대한 이점은 있겠지만요)
즉, 층 사이의 입출력을 구분 지어 층마다의 관계를 비선형적으로 바꿔내서 층을 깊게 쌓은 것에 대한 결과를 단순한 선형적인 함수가 아닌 복잡성을 가져서 좋은 결과를 얻어내기 위해 Activation을 비선형적 함수로 사용하는 것입니다.
Non-linear Model과 hidden-layer로 구분 지어 말했지만 결론적으로 둘 다 같은 말을 합니다.
비선형적 함수를 사용하게 됨으로써 모델의 복잡성을 늘리고,
이로 인해 보다 더 정확한 분류를 하게 하는 것이 Activation의 목적입니다.
✅ Back-Propagation의 관점
더군다나 선형 함수로 Activation으로 고르는 것을 생각했을 때,
Back-Propagation에서 선형 함수의 미분값은 계속 같은 상수값만 주기 때문에 학습이 잘 되지도 않을 겁니다.
$$ \frac{\partial a}{\partial z} = constant $$
✅ Reference
https://syj9700.tistory.com/37
활성화 함수(Activation Function)
○ 활성화 함수 활성화 함수는 이전 층(layer)의 결과값을 변환하여 다른 층의 뉴런으로 신호를 전달하는 역할을 한다. 활성화 함수가 필요한 이유는 모델의 복잡도를 올리기 위함인데 앞서 다루
syj9700.tistory.com
딥러닝 기본 개념 - 신경망 구조, 활성화 함수, Optimizer
📚 신경망 기본 구조 및 용어 설명 ✅ 입력층, 은닉층, 출력층 설명 ① 입력층(Input Layer) - feature에 대한 정보(독립변수)를 입력받고 다음 층으로 전달한다. - 입력층 노드의 수 = 독립변수의 수 ②
yeong-jin-data-blog.tistory.com
https://ganghee-lee.tistory.com/30
활성화 함수(activation function)을 사용하는 이유
신경망모델의 각 layer에서는 input 값과 W, b를 곱, 합연산을 통해 a=WX+b를 계산하고 마지막에 활성화 함수를 거쳐 h(a)를 출력한다. 이렇게 각 layer마다 sigmoid, softmax, relu 등.. 여러 활성화 함수를 이
ganghee-lee.tistory.com
'AI > Concepts' 카테고리의 다른 글
| Transfer Learning(pre-training, fine-tuning)의 개념에 대하여 (Prologue) (0) | 2023.02.04 |
|---|---|
| Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (4) | 2023.01.22 |
| Gradient Vanishing / Exploding에 대하여 (1) | 2023.01.17 |
| Back-Propagation(역전파)에 대하여 (1) | 2023.01.16 |
| Batch Normalization이란? (Basic) (0) | 2023.01.02 |


