
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 분할 정복
- BFS
- 문자열
- 자바스크립트
- object detection
- lazy propagation
- DP
- 2023
- 다익스트라
- NEXT
- 조합론
- 미래는_현재와_과거로
- 가끔은 말로
- 세그먼트 트리
- 회고록
- dfs
- Overfitting
- 크루스칼
- 우선 순위 큐
- 가끔은_말로
- back propagation
- 백트래킹
- 플로이드 와샬
- tensorflow
- c++
- 너비 우선 탐색
- dropout
- pytorch
- 이분 탐색
- 알고리즘
- Today
- Total
Doby's Lab
[알고리즘] 백준 15663번: N과 M (9) (C++), 도식화의 중요성 본문
(추가 내용 2021.11.15)
https://draw-code-boy.tistory.com/96
[알고리즘] 백준 6443번: 애너그램 (C++), 백트래킹 중복 처리 유형 2번째!
https://www.acmicpc.net/problem/6443 6443번: 애너그램 첫째 줄에 단어의 개수 N 이, 둘째 줄부터 N개의 영단어가 들어온다. 영단어는 소문자로 이루어져 있다. 단어의 길이는 20보다 작거나 같고, 애너그램
draw-code-boy.tistory.com
비슷한 문제가 나와서 정리해두었다.
백트래킹의 코드 구조를 익히면서 [N과 M 시리즈]를 풀고 있었다.
이번 문제에서 막히게 되었는데 해당 문제에서 이런 걸 요구했기 때문이다.
'N이 4이고, M이 2일 때, 9 7 9 1의 수들로 부분 수열을 구하라'라는 예제를 돌리면서 막혔다.
문제의 키워드는
1. 수열은 사전 순으로 증가하는 순서대로 출력 => 정렬 및 visited 배열 선언 후 중복 여부 확인
2. 중복되는 수열을 여러 번 출력하면 안 됨 => 결과물들 배열에 담아서 중복되는 수열 제거하여야 하나?
2번 키워드가 막히게 되는 요인이었는데 1번 키워드까지 구현했던 코드는 이렇다.
#include <iostream>
#include <vector>
#include <algorithm>
#define MAX 8
using namespace std;
int n, m;
int arr[MAX] = { 0, };
bool visited[MAX] = { 0, };
void dfs(int num, vector<int> nums, int cnt) {
if (cnt == m) {
for (int i = 0; i < m; i++) {
cout << arr[i] << ' ';
}
cout << '\n';
return;
}
for (int i = num; i < n; i++) {
if (!visited[i]) {
visited[i] = true;
arr[cnt] = nums[i];
dfs(num, nums, cnt + 1);
visited[i] = false;
}
}
}
int main() {
cin >> n >> m;
vector<int> nums;
for (int i = 0; i < n; i++) {
int a;
cin >> a;
nums.push_back(a);
}
sort(nums.begin(), nums.end());
dfs(0, nums, 0);
return 0;
}예제
input
4 2
9 7 9 1
output
1 7
1 9
1 9
7 1
7 9
7 9
9 1
9 7
9 9
9 1
9 7
9 9
중복되는 수열들을 어찌 처리할까 고민하다가 '코드의 측면'에서 한참 바라봤다.
[코드의 측면 1]
'저 output으로 나온 수열들을 2차원 배열에 넣어서 중복되는 걸 없애야 하나'
'그럼 반환형이 vector형이어야 하는데 그럼 재귀 호출이 가능해질까'
'그렇게 되면 코드 구조를 싹 다 갈아치워야 하는데 이런 식으로 접근하는 건 아닌 듯하다'
라는 생각까지 이르렀다.
[코드의 측면 2]
'그럼 함수를 돌리기 전에 중복되는 걸 없애야 하는 걸까'라는 고민을 해보면
다행스럽게도 '9 9'라는 부분 수열이 있었기 때문에 잘못 접근할 뻔하다가 빠져나왔다.
>> '중복되는 수가 아니라 중복되는 수열'임을 잠시 인지하지 못했었던 거 같다.
그렇다면 논리의 부족함이 맞는데 적합한 논리가 떠오르지 않아 다른 분들의 코드를 참고했다.
이번 문제에서 생각만 하고 있던 잠재적인 문제들을 체감할 수 있었다.
https://myunji.tistory.com/309
[백준] 15663번 : N과 M (9)
문제 풀이 예제 입력 2에 대해 그냥 중복 상관없이 모든 수열을 사전순으로 출력하면 1 7 1 9 1 9 7 1 7 9 7 9 9 1 9 7 9 9 9 1 9 7 9 9 가 될 것이다. 여기서 중복을 제거해야 하는데 처음엔 아무리 머리를 굴
myunji.tistory.com
너무 설명이 잘 되어있던 포스팅이었다.
#include <iostream>
#include <algorithm>
using namespace std;
int input[8], arr[8];
int N, M;
bool visited[8];
void backtracking(int num) {
if (num == M) { //출력
for (int i = 0; i < M; i++)
cout << arr[i] << ' ';
cout << '\n';
return;
}
int value = -1; //이전에 선택한 값 기억
for (int i = 0; i < N; i++) {
if (!visited[i] && (value != input[i])) { //방문 여부와 함께 이전 탐색 여부도 검사
value = input[i];
visited[i] = true; //visited 처리
arr[num] = input[i];
backtracking(num + 1);
visited[i] = false; //unvisited 처리
}
}
}
int main() {
cin >> N >> M;
for (int i = 0; i < N; i++)
cin >> input[i];
sort(input, input + N); //정렬
backtracking(0);
}이 문제에서 특별하게 사용됐던 논리는 백트래킹을 돌리기 전에 정렬이 되어있기 때문에
내가 쓴 코드의 아웃풋을 보면
output
1 7
1 9
1 9
7 1
7 9
7 9
9 1
9 7
9 9
9 1
9 7
9 9
백트래킹을 돌리게 되면서 같은 숫자들의 수열이 바로 다음에 출력이 되는 것인데
이를 활용하여 제거를 하면 된다. 그림으로 나타내 보면
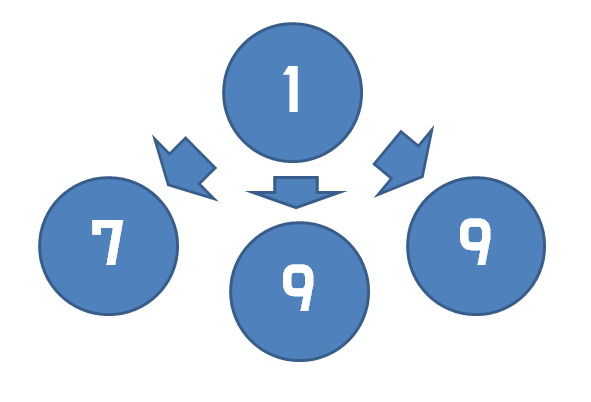
output에서
1 7
1 9
1 9
가 나올 때
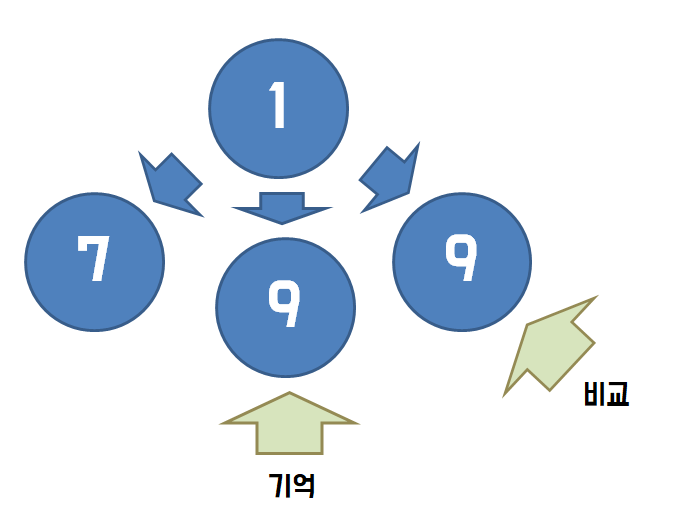
바로 전에 나왔던 직전 노드들을 기억하고 다음 노드에서 이와 비교하여 중복을 없애는 것이다.
즉, 코드에서 설명하자면
#include <iostream>
#include <vector>
#include <algorithm>
#define MAX 8
using namespace std;
int n, m;
int arr[MAX] = { 0, };
bool visited[MAX] = { 0, };
void dfs(int num, vector<int> nums, int cnt) {
if (cnt == m) {
for (int i = 0; i < m; i++) {
cout << arr[i] << ' ';
}
cout << '\n';
return;
}
int before = -1; //여기서 직전 노드를 넣어줄 수 있는 변수 선언
for (int i = num; i < n; i++) {
if (!visited[i] && nums[i] != before) {//지금 넣으려는 노드 nums[i]와 과거 노드 before이 다르다는 조건
visited[i] = true;
arr[cnt] = nums[i];
before = arr[cnt];//다음 비교를 위해 지금 노드를 before에다가 넣어줌
dfs(num, nums, cnt + 1);
visited[i] = false;
}
}
}
int main() {
cin >> n >> m;
vector<int> nums;
for (int i = 0; i < n; i++) {
int a;
cin >> a;
nums.push_back(a);
}
sort(nums.begin(), nums.end());
dfs(0, nums, 0);
return 0;
}주석으로 설명된 부분이 이번 문제 핵심이었다.
느낀 점
위에서 이번 문제에서 잠재적으로 걱정하던 문제들이 터진 거 같다고 했었는데 이러한 문제들이었다.
- 논리적인 접근이 아닌 코드적인 측면에서 접근을 하려 한다는 점
- 코드를 보면서 논리 접근을 하려 한다던 점
- 도식화가 되지 않던 점
이 3개가 거의 하나처럼 느껴지긴 한다. 첫 backtracking 포스팅에서 코드 부분이 이해가 되지 않아 시뮬레이션으로 하나하나 직접 써보면서 포스팅을 했었는데 시뮬레이션을 하기 전에 계속했던 생각이 '이 코드를 어떻게 도식화를 할 수 있을까' 였었다. 도식화가 되지 않아서 결국 시뮬레이션을 반복하면서 이해를 해보자 했었다. 도식화가 정말 중요하다고 생각하는 이유가 항상 나는 논리가 막힐 때 코드를 보면서 어느 부분에 막혔을까를 고민했다. 하지만, 코드를 보며 머릿속으로 그리면서 머리로 컴파일(?)하는 과정이 시간을 엄청 잡아먹는다. 도식화를 하면서 더 빠르고 효율적으로 문제를 풀어나갈 수 있기 때문에 도식화를 더 신경 써봐야겠다고 느꼈다.
그리고, 링크를 걸어두었던 곳에 백트래킹 도식화를 보고서 시작 노드를 0으로 두고서 간단하게 도식화했다는 점이 내 머리를 세게 쳤다. '코드도 그렇고, 도식화도 내가 이해만 할 수 있으면 되겠다'를 느꼈다.
'PS > BOJ' 카테고리의 다른 글
| [알고리즘] 백준 2343번: 기타레슨 (C++), 다른 사람 코드는 귀한 교과서 (0) | 2021.09.24 |
|---|---|
| [자료구조] 백준 17298번: 오큰수 (C++), Monotonic Stack (단조로운 스택) (0) | 2021.09.22 |
| [알고리즘] 백준 15650번: N과 M (2) (C++), Backtracking의 개념, DFS와의 차이 (0) | 2021.09.16 |
| [알고리즘] 백준 2110번: 공유기 설치 (C++), (low + 1 < high)라는 조건, 논리의 부족 (0) | 2021.09.14 |
| [알고리즘] 백준 2805번: 나무 자르기 (C++), 이분 탐색 (함수 없이 직접 구현) (0) | 2021.09.13 |



